
The outcome
A credible defect detection system in manufacturing should deliver four non-negotiables:
Consistent capture → consistent predictions (poor capture conditions destroy model quality).
Clear model lifecycle (train, validate, deploy, monitor, retrain).
Real-time + batch flexibility (some lines need immediate decisions; others run audits overnight).
Actionable outputs (alerts, dashboards, and write-backs into MES/QMS workflows).
The AWS architecture is designed around exactly those constraints.
Architecture at a glance (what’s happening end-to-end)
1) Image capture on the shop floor (device tier)
The process starts where quality begins: X-ray machines, cameras, and other inspection devices operating under consistent capture conditions. Consistency matters more than people expect—lighting, angle, exposure, calibration, and part positioning can make or break model performance.
Intelliblitz note: Before we touch ML, we standardize capture. We treat it like an engineering spec, not an “operator preference.”
2) Transfer from edge to AWS (edge tier ingestion)
The architecture supports multiple ingestion paths depending on what your plant already runs:
AWS Transfer Family (managed file transfer patterns)
AWS DataSync (reliable, large-scale data movement)
AWS IoT Greengrass (especially useful when images are produced at the edge and you want local control + secure sync)
This is practical: different plants have different operational realities. The system shouldn’t force a single ingestion pattern.
3) Central storage and dataset management in Amazon S3
All images land in Amazon S3, where they’re organized into datasets—typically split into training and test/validationsets (and in mature systems: versioned datasets by line, plant, supplier, or part revision).
S3 becomes your system of record for:
Raw images
Labeled datasets
Inference outputs (predictions, scores, metadata)
Audit trails for compliance
Intelliblitz note: We implement a dataset structure that supports traceability (part ID, batch/lot, timestamp, line, tool calibration version). This is what makes audits and root-cause analysis possible later.
4) Model training with Amazon Lookout for Vision
Amazon Lookout for Vision is used to:
Assist with labeling workflows
Train and tune the defect detection model
Deploy the trained model for inference
This reduces the barrier to entry for industrial anomaly detection—especially for teams that don’t want to build a full custom vision training stack from scratch.
5) Expose and manage the model via AWS Lambda + Amazon API Gateway
Once trained, the architecture exposes model management and interaction through:
AWS Lambda (for management logic / lightweight control plane actions)
Amazon API Gateway (to provide a clean API layer for admins and data teams)
This is important because production deployments need controlled access, logging, and governance—not “someone running notebooks.”
Inference paths: real-time, orchestrated, and batch
6) Serverless orchestration for inference (AWS Step Functions + Lambda)
For runtime defect detection, the architecture uses AWS Step Functions to orchestrate inference workflows with Lambda.
Why this matters:
Step Functions gives you repeatable orchestration and visibility
Lambda provides modular “glue” logic: preprocess, call inference, postprocess, route outputs
This creates a scalable pattern for event-driven inspection pipelines.
7) Batch anomaly detection (AWS Batch + AWS Fargate)
Not every inspection needs real-time decisions. Many manufacturers run:
Batch analysis per shift
Supplier audits
Re-inspection of borderline items
Retrospective analysis after a quality incident
Here the architecture supports AWS Batch, with compute provisioned using AWS Fargate, so you can scale batch workloads without managing servers.
8) Alerts and confidence-based notifications (Amazon SNS)
The system notifies users using Amazon SNS—and crucially, it can route alerts based on confidence thresholds.
A mature quality workflow doesn’t treat predictions as binary. It treats them as:
High confidence defect → immediate action
Medium confidence → human review queue
Low confidence → label for future retraining / capture conditions check
This is how you reduce false positives without becoming blind to real defects.
9) Results storage, visualization, and shop-floor write-back (S3 + QuickSight + MES integration)
Finally, results can be:
Stored back in Amazon S3
Visualized for business and quality users in Amazon QuickSight
Written back into the MES through an integration step (commonly via AWS Lambda)
This closes the loop—from inspection → decision → reporting → operational action.
Intelliblitz note: Dashboards are not the finish line. The finish line is “the line behavior changes automatically” (hold/rework routing, supplier scoring, CAPA triggers, operator prompts).
What separates a demo from a production system
Most “AI defect detection” projects fail not because the model is bad—but because the surrounding system is weak. Here’s what we add when we implement this architecture for real clients:
Data governance and traceability
Dataset versioning and lineage (what model was trained on what data)
Immutable audit logs for regulated environments
Role-based access for images, labels, and predictions
MLOps and model lifecycle discipline
Automated evaluation gates before deployment
Drift monitoring (capture drift, supplier drift, process drift)
Retraining cadence tied to business events (new tooling, new supplier, new part revision)
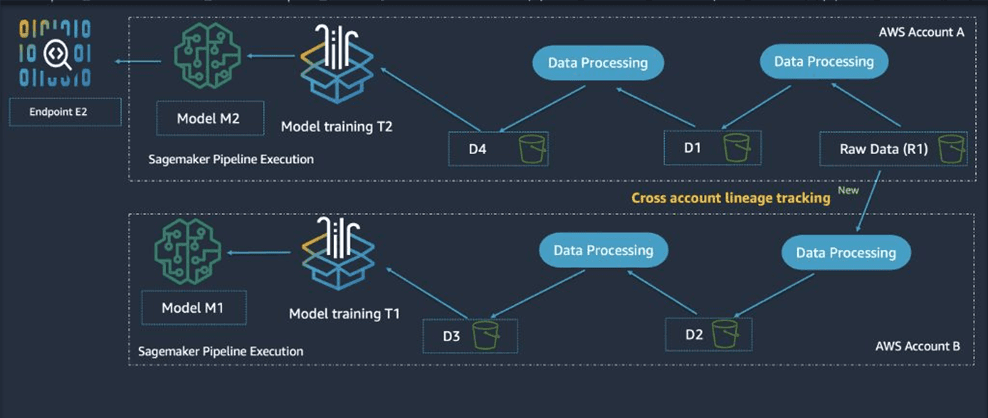
Human-in-the-loop workflows
A review queue for borderline predictions
Labeling feedback loops that improve the model weekly (not yearly)
Operator-friendly UI patterns that don’t slow the line down
Real ROI measurement
We instrument the system to quantify:
Scrap reduction
Yield improvement
Reduced rework time
Faster containment during quality events
Reduced inspection labor hours (or reallocated to higher-value tasks)


